Yesterday, the Synthesio Coffee Team finished upgrading a 22TB MySQL cluster from Percona 5.6 to Percona 5.7. We already upgraded most of our clusters and knew that one would take time, but we didn’t expect it to take 9 full months. This is what we have learned about migrating giant database clusters without downtime.
The initial setup
Our database cluster is a classic high availability 3 + 1 nodes topology running behind Haproxy. It runs on a Debian Jessie without Systemd with a 4.9.1 kernel (4.4.36 at the beginning). The servers have a 20 core Dual Xeon E5–2660 v3 with 256GB RAM and 36 * 4TB hard drive setup as a RAID10. The throughput is around 100 million writes / day, inserts and updates mixed.
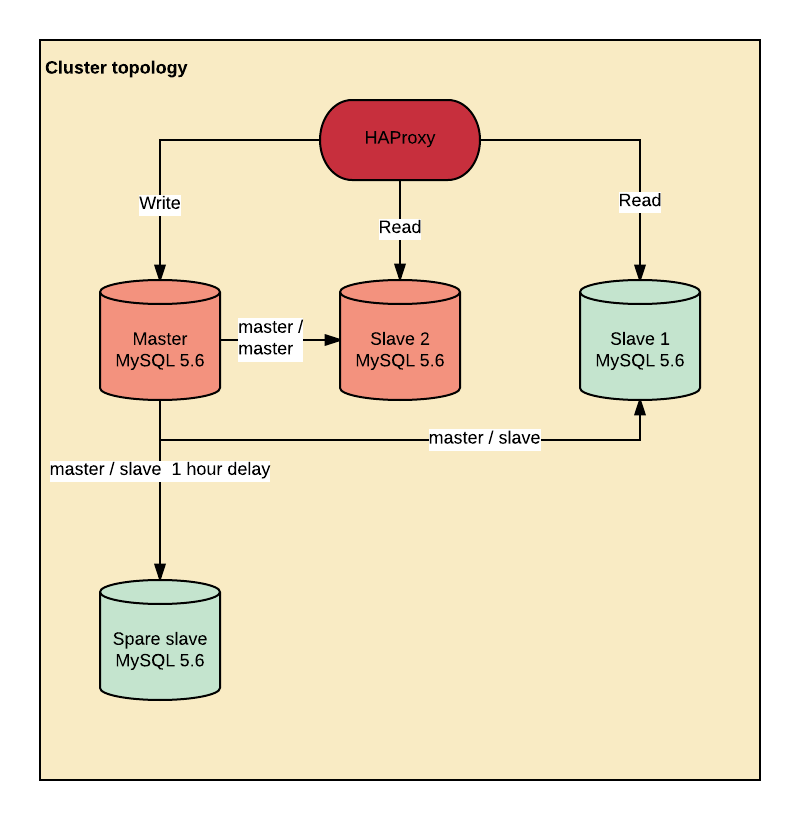
The cluster design itself has nothing special:
- 2 servers are configured as master / master, but writes are performed on the main master only.
- Reads are performed on the master and both slaves via a Haproxyconfigured to remove a slave when the replication lags.
- A spare slave is running offsite with MASTER_DELAY set to 1 hour in case the little Bobby Tables plays with our servers.
Step 1: in the hell of mysql_upgrade
We upgraded the spare host to MySQL 5.7 using Percona Debian packages.

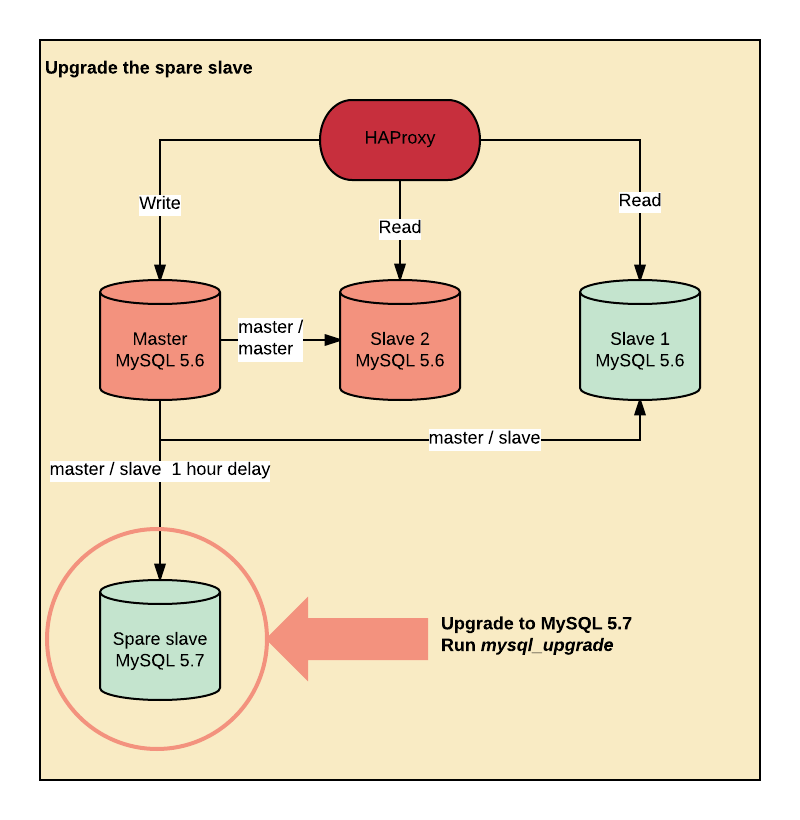
Upgrading from MySQL 5.6 to MySQL 5.7 requires to upgrade every table having TIME, DATETIME, and TIMESTAMP columns to add support for fractional seconds precision. mysql_upgrade handles that part as well as the system tables upgrade.
Upgrading tables with temporal columns means running an ALTER TABLE … FORCE on every table that requires the upgrade. It meant copying 22TB of data as temporary tables, then load the data back. On spinning disks.
After 5 months, we were 20% done.
We killed mysql_upgrade and wrote a script to run the ALTER on 2 tables in parallel.
2 months later, the upgrade was 50% done and the replication lag around 9 million seconds. A massive replication lag was not in the plans, and it introduced a major unexpected delay in the process.
We decided to upgrade our hardware a bit.
We installed a new host with 12 * 3.8TB SSD disks in RAID0 (don’t do this at home), rsynced the data from the spare host and resumed the process. 8 days later, the upgrade was over. It took 3 more weeks to catch up with the replication.
Step 2: adding 2 new MySQL 5.7 slaves
Before doing this, make sure your cluster has the GTID activated. GTID saved us lots of time and headache as we reconfigured the replication a couple of times. Not sure about friendship, but MASTER_AUTO_POSITION=1 is magic.
We added 2 new slaves running MySQL 5.7. There’s a bug with Percona postinst.sh script when installing a fresh server with MySQL data not in /var/lib/mysql. The database path is hardcoded in the shell script, which cause the install to hang forever. The bug can be bypassed by installing percona-server-server-5.6, then installing percona-server-server-5.7.
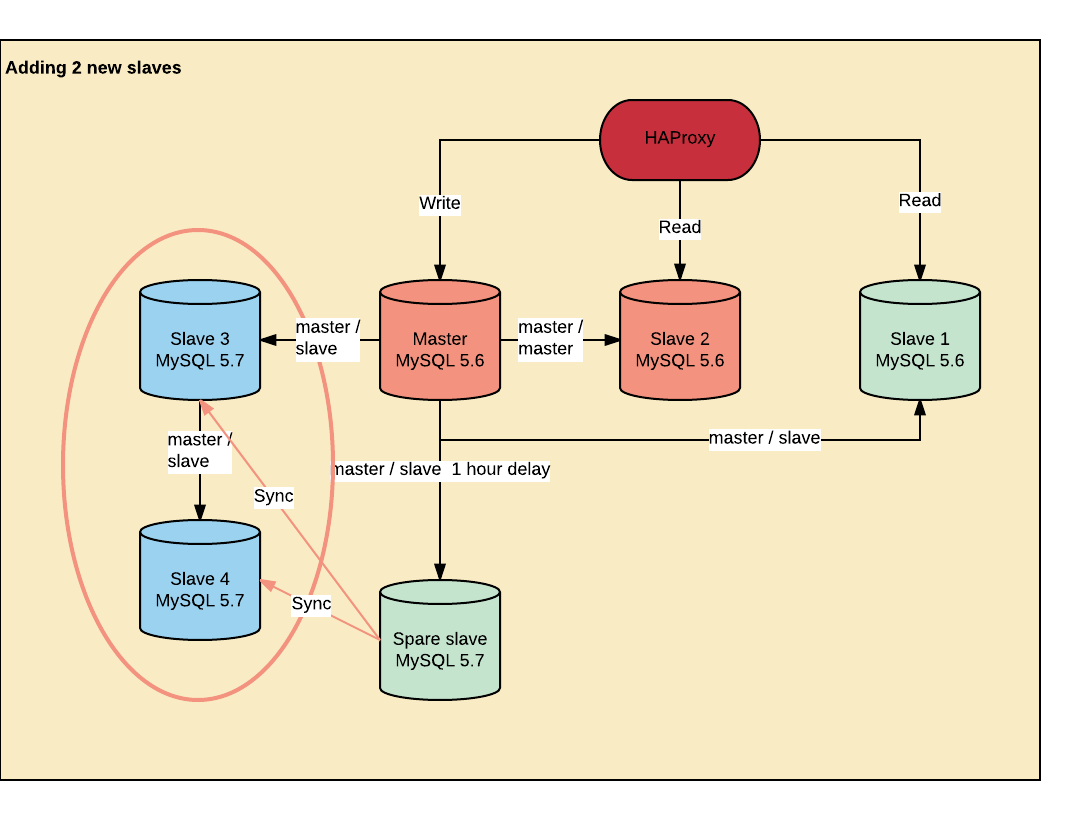
Once done, we synced the data from the MySQL 5.7 spare host to the new slaves running innobackupex.
On the receiver:
mysql -e "SET GLOBAL expire_logs_days=7;"
nc -l -p 9999 | xbstream -x
On the sender:
innobackupex --stream=xbstream -- parallel=8 ./ | nc slave[3,4] 9999
30 hours later:
innobackupex --use-memory=200G --apply-log .
On Slave 3:
CHANGE MASTER TO
MASTER_HOST="master",
MASTER_USER="user",
MASTER_PASSWORD="password",
MASTER_AUTO_POSITION=1;
On slave 4:
CHANGE MASTER TO
MASTER_HOST="slave 3",
MASTER_USER="user",
MASTER_PASSWORD="password",
MASTER_AUTO_POSITION=1;
Step 3: catching up with the replication (again)
Once again, we were late on the replication. I already wrote about fixing a lagging MySQL replication. Please read carefully the pros and cons before you apply the following configuration:
STOP SLAVE;
SET GLOBAL sync_binlog=0;
SET GLOBAL innodb_flush_log_at_trx_commit=2;
SET GLOBAL innodb_flush_log_at_timeout=1800;
SET GLOBAL slave_parallel_workers=40;
START SLAVE;
Catching up with the replication on both hosts took 2 to 3 weeks mostly because we had much more writes than we usually do.
Step 4: finishing the job
The migration was almost done. There were a few things left to do.
We reconfigured Haproxy to switch the writes on slave 3, which de facto became the new master and the reads on slave 4. Then, we restarted all the writing processes on the platform to kill the remaining connections.
After 5 minutes, slave 3 had caught up with everything from master, and we stopped the replication. We saved the last transaction ID from master in case we would have to rollback.
Then, we reconfigured slave 3 replication to make it a slave of slave 4, so we would run in a master / master configuration again.
We upgraded master in MySQL 5.7, ran innobackupex again and made it a slave of slave 3. The replication took a few days to catch up, then, yesterday, we added master back in the cluster.
After one week, we trashed slave 1 and slave 2 which were no use anymore.


Rollback, did someone say “rollback”?
My old Chinese master had a proverb for every migration:
A good migration goes well but a great migration expects a rollback.
If something got wrong, we had a plan B.
When swithing, we kept the last transaction ran on master, and master was still connected to slave 1 and slave 2. In case or problem, we would have stopped everything, exported the missing transactions, loaded the data and switched back to the origin master + slave 1 + slave 2. Thankfully, this is not something we had to do. Next time, I’ll tell you how we migrated a 6TB Galera cluster from MySQL 5.5 to MySQL 5.7. But later.

No comments:
Post a Comment