MySQL InnoDB cluster provides a complete high availability solution for MySQL.Each MySQL server instance runs MySQL Group Replication, which provides the mechanism to replicate data within InnoDB clusters, with built-in failover.
This work instruction details the steps to setting up a cluster MySQL InnoDB, how to manage IT and the recovering procedure in case of failure.
Deployment of InnoDB Cluster
We will create a 3 member Group Replication cluster with them and setup MySQL Router as a proxy to hide the multiple MySQL instances behind a single TCP port.
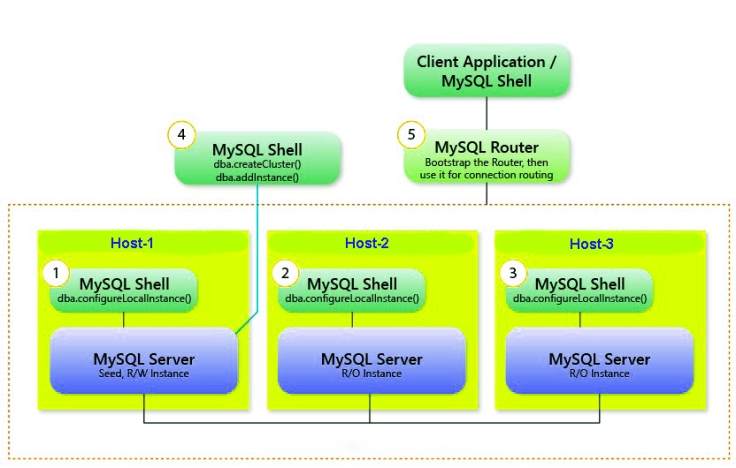
The user account used to administer an instance does not have to be the root account, however the user needs to be assigned full read and write privileges on the InnoDB cluster metadata tables in addition to full MySQL administrator privileges (SUPER, GRANT OPTION, CREATE, DROP and so on).
CREATE USER innodbuser@'%' IDENTIFIED BY 'user_Password' ; GRANT ALL PRIVILEGES ON mysql_innodb_cluster_metadata.* TO TO innodbuser@'%' WITH GRANT OPTION; GRANT RELOAD, SHUTDOWN, PROCESS, FILE, SUPER, REPLICATION SLAVE, REPLICATION CLIENT, \ CREATE USER ON *.* TO innodbuser@'%' WITH GRANT OPTION; GRANT SELECT ON *.* TO innodbuser@'%' WITH GRANT OPTION;
If only read operations are needed (such as for monitoring purposes), an account with more restricted privileges can be used.
GRANT SELECT ON mysql_innodb_cluster_metadata.* TO innodbuser@'%'; GRANT SELECT ON performance_schema.global_status TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_applier_configuration TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_applier_status TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_applier_status_by_coordinator TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_applier_status_by_worker TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_connection_configuration TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_connection_status TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_group_member_stats TO innodbuser@'%'; GRANT SELECT ON performance_schema.replication_group_members TO innodbuser@'%'; GRANT SELECT ON performance_schema.threads TO innodbuser@'%' WITH GRANT OPTION;
When working with a production deployment it can be useful to configure verbose logging for MySQL Shell
shell> mysqlsh --log-level=DEBUG3
First, we will check the configuration of one of our MySQL server. Some changes are required, we will perform them using the Shell and we will restart mysqld:
# mysqlsh
mysql-js> dba.checkInstanceConfiguration('innobuser@prodserver1:3306')
AdminAPI provides the dba.configureLocalInstance() function that finds the MySQL server’s option file and modifies it to ensure that the instance is correctly configured for InnoDB cluster.
mysql-js> dba.configureLocalInstance('innobuser@prodserver1:3306')
Restart the mysqld service
$ systemctl restart mysqld
Repeat this process for each server instance that you added to the cluster.
To persist the InnoDB cluster metadata for all instances, log in to each instance that you added to the cluster and run MySQL Shell locally.
# mysqlsh mysql-js> var i1='innobuser@prodserver1:3306' mysql-js> var i2='innobuser@prodserver2:3306' mysql-js> var i3='innobuser@prodserver3:3306' mysql-js> shell.connect(i1)
mysql-js> var cluster = dba.createCluster('prodcluster')
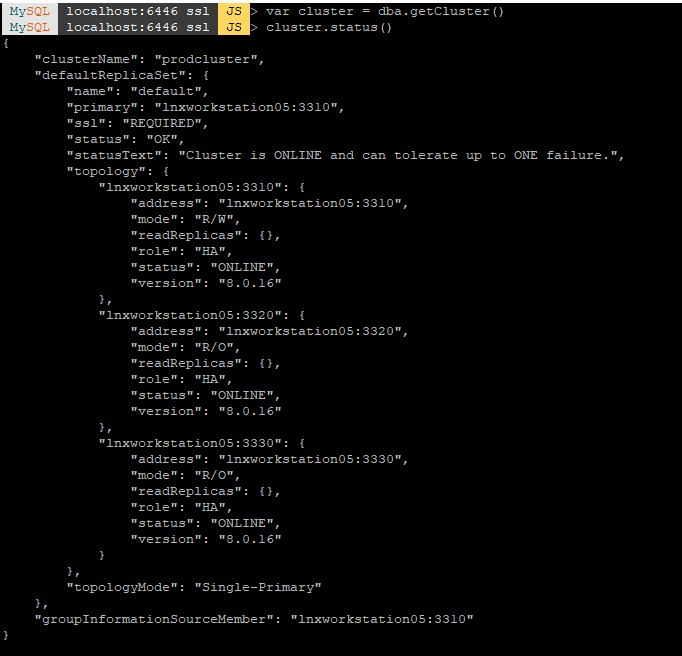
To check the cluster has been created, use the cluster instance’s status() function.
mysql-js> cluster.status()
Use the cluster.addInstance(instance) function to add more instances to the cluster, where instance is a URI type string to connect to the local instance.
mysql-js> cluster.addInstance(i2) mysql-js> cluster.addInstance(i3)
Check the current status of the InnoDB cluster and produces a short report. The status field for each instance should show either ONLINE or RECOVERING. RECOVERING means that the instance is receiving updates from the seed instance and should eventually switch to ONLINE.
mysql-js> cluster.status()
{
"clusterName": "prodcluster",
"defaultReplicaSet": {
"name": "default",
"primary": "prodserver1:3306",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"prodserver1:3306": {
"address": "prodserver1:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"prodserver2:3306": {
"address": "prodserver2:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"prodserver3:3306": {
"address": "prodserver3:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
}
}
MySQL Router uses the included metadata cache plugin to retrieve the InnoDB cluster’s metadata, consisting of a list of server instance addresses which make up the InnoDB cluster and their role in the cluster.
$ sudo mysqlrouter --bootstrap innobuser@prodserver1:3306 --directory /mysqlrouter --user=mysq
Once bootstrapped and configured, start MySQL Router:
/mysqlrouter/start.sh
Cluster Management
Checking Status of the InnoDB Cluster
To check the status of the InnoDB cluster at a later time, you can get a reference to the InnoDB cluster object by connecting to the cluster through the Router or directly to one of the instances.
mysql-js> var cluster = dba.getCluster() mysql-js> cluster.status()
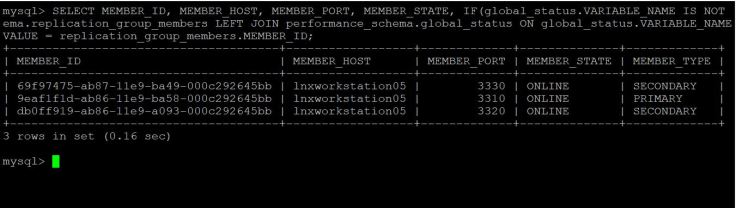
From MySQL SQL command line interface we can we the below command to check the cluster health.
SELECT MEMBER_ID, MEMBER_HOST, MEMBER_PORT, MEMBER_STATE, IF(global_status.VARIABLE_NAME IS NOT NULL, 'PRIMARY', 'SECONDARY') AS MEMBER_TYPE FROM performance_schema.replication_group_members LEFT JOIN performance_schema.global_status ON global_status.VARIABLE_NAME = 'group_replication_primary_member' AND global_status.VARIABLE_VALUE = replication_group_members.MEMBER_ID;
The group states shown by the cluster.status() command are:
OK – is shown when all members belonging are ONLINE and there is enough redundancy to tolerate at least one failure.
OK_PARTIAL – when one or more members are unavailable, but there’s still enough
redundancy to tolerate at least one failure.
OK_NO_TOLERANCE – when there are enough ONLINE members for a quorum to be
available, but there’s no redundancy. A two member group has no tolerance, because if one of them becomes UNREACHABLE, the other member can’t form a majority by itself;
which means you will have a database outage. But unlike in a single member group, at least your data will still be safe on at least one of the nodes.
NO_QUORUM – one or more members may still be ONLINE, but cannot form a quorum.
In this state, your cluster is unavailable for writes, since transactions cannot be executed.
However, read-only queries can still be executed and your data is intact and safe.
UNKNOWN – this state is shown if you’re executing the status() command from an
instance that is not ONLINE or RECOVERING. In that case, try connecting to a different
member.
UNAVAILABLE – this state is shown in the diagram but will not be displayed by the
cluster.status() command. In this state, ALL members of the group are OFFLINE. They
may still be running, but they’re not part of the group anymore. This can happen if all
members restart without rejoining, for example.
OK – is shown when all members belonging are ONLINE and there is enough redundancy to tolerate at least one failure.
OK_PARTIAL – when one or more members are unavailable, but there’s still enough
redundancy to tolerate at least one failure.
OK_NO_TOLERANCE – when there are enough ONLINE members for a quorum to be
available, but there’s no redundancy. A two member group has no tolerance, because if one of them becomes UNREACHABLE, the other member can’t form a majority by itself;
which means you will have a database outage. But unlike in a single member group, at least your data will still be safe on at least one of the nodes.
NO_QUORUM – one or more members may still be ONLINE, but cannot form a quorum.
In this state, your cluster is unavailable for writes, since transactions cannot be executed.
However, read-only queries can still be executed and your data is intact and safe.
UNKNOWN – this state is shown if you’re executing the status() command from an
instance that is not ONLINE or RECOVERING. In that case, try connecting to a different
member.
UNAVAILABLE – this state is shown in the diagram but will not be displayed by the
cluster.status() command. In this state, ALL members of the group are OFFLINE. They
may still be running, but they’re not part of the group anymore. This can happen if all
members restart without rejoining, for example.
Recovering from Failures
If mysqld restarts for any reason (crash, expected restart, reconfiguration etc), it will NOT be in the group anymore when it comes back up. It needs to rejoin it, which may have to be done manually in some cases. For that, you can use the cluster.rejoinInstance()
Whenever Group Replication stops, the super_read_only variable is set to ON to ensure no writes are made to the instance.
Rejoining a Cluster
If an instance leaves the cluster, for example because it lost connection and did not or could not automatically rejoin the cluster, it might be necessary to rejoin it to the cluster at a later stage. To rejoin an instance to a cluster issue cluster.rejoinInstance().
mysql-js> dba.validateInstance('innobuser@prodserver1:3306')
mysql-js> cluster.rejoinInstance('innobuser@prodserver1:3306');
Restoring a Cluster from Quorum Loss
If so many members of your replica set become UNREACHABLE that it doesn’t have a majority anymore, it will no longer have a quorum and can’t take decisions on any changes. That includes user transactions, but also changes to the group’s topology. That means that even if a member that became UNREACHABLE returns, it will be unable to rejoin the group for as long as the group is blocked.
To recover from that scenario, we must first unblock the group, by re configuring it to only consider the currently ONLINE members and ignore all others. To do that, use the cluster.forceQuorumUsingPartitionOf() command, by passing the URI of one of the ONLINE members of your replica set. All members that are visible as ONLINE from that member will be added to the redefined group.
Note : “Be careful that the best practice is to shutdown the other nodes to avoid any kind of conflicts if they reappear during the process of forcing quorum”
If you want to know if your MySQL server is part of the primary partition (the one having the majority), you can run this command:
mysql> SELECT IF( MEMBER_STATE='ONLINE' AND ((
SELECT COUNT(*) FROM performance_schema.replication_group_members
WHERE MEMBER_STATE NOT IN ('ONLINE', 'RECOVERING')) >=
((SELECT COUNT(*)
FROM performance_schema.replication_group_members)/2) = 0), 'YES', 'NO' )
` in primary partition` FROM performance_schema.replication_group_members JOIN performance_schema.replication_group_member_stats USING(member_id) where member_id=@@global.server_uuid;
Retrieve metadata from a cluster
SELECT cluster_name FROM mysql_innodb_cluster_metadata.clusters; SELECT host_name FROM mysql_innodb_cluster_metadata.hosts;
Shutdown the defective nodes first and run the cluster.forceQuorumUsingPartitionOf() command in online node.
$ mysqlsh --uri=root@prodserver1:3306
mysql-js> var cluster = dba.getCluster("prodcluster")
mysql-js> cluster.forceQuorumUsingPartitionOf('root@prodserver1:3306')
mysql-js> cluster.status()
mysql-js> cluster.rejoinInstance('root@prodserver2:3306')
mysql-js> cluster.rejoinInstance('root@prodserver3:3306')
To avoid split brain best solution to prevent the nodes not being part of the the forced quorum partition to agree making their own group as they will have a majority.
set global group_replication_unreachable_majority_timeout=30; set global group_replication_exit_state_action = 'ABORT_SERVER';
This means that if there a problem and the node is not able to join the majority after 30 seconds it will go in ERROR state and then shutdown `mysqld`.
Rebooting a Cluster from a Major Outage
If your cluster suffers from a complete outage, you can ensure it is reconfigured correctly using dba.rebootClusterFromCompleteOutage().
Make sure that all the three instances are up and running
mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+--------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+--------------+-------------+--------------+ | group_replication_applier | 516d2ea6-0d94-11e8-825b-000c2958682d | prodserver1 | 3306 | OFFLINE | | group_replication_applier | d4786d8c-0d9e-11e8-b10c-000c2958682d | prodserver2 | 3306 | OFFLINE | | group_replication_applier | da2d0b92-0d8a-11e8-bc4c-000c2958682d | prodserver3 | 3306 | OFFLINE | +---------------------------+--------------------------------------+--------------+-------------+--------------+ 3 rows in set (0.00 sec)
mysql-js> var i1='innobuser@prodserver1:3306'
mysql-js> shell.connect(i1)
mysql-js> dba.rebootClusterFromCompleteOutage('prodcluster')
mysql-js> var cluster = dba.getCluster() mysql-js> cluster.status()
Checking current cluster configuration options
mysql-js> cluster.options()
Changing cluster members or global cluster options
cluster.setOption(option, value)
The accepted values for the configuration option are:
- clusterName: string value to define the cluster name.
- exitStateAction: string value indicating the group replication exit state action.
- memberWeight: integer value with a percentage weight for the automatic primary election on failover.
- failoverConsistency: string value indicating the consistency guarantees for primary failover in single primary mode.
- expelTimeout: integer value to define the time period in seconds that cluster members should wait for a non-responding member before evicting it from the cluster.

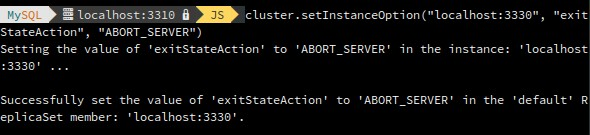
cluster.setInstanceOption(instance, option, value)
The accepted values for the configuration option are:
- label: a string identifier of the instance.
- exitStateAction: string value indicating the group replication exit state action.
- memberWeight: integer value with a percentage weight for the automatic primary election on failover.
Changing cluster topology modes
Switch cluster to single-primary mode.
mysql-js> var cluster = dba.getCluster() mysql-js> cluster.switchToSinglePrimaryMode() mysql-js> cluster.status()
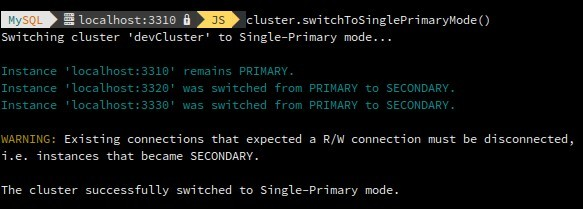
Switches a cluster to multi-primary mode.
mysql-js> var cluster = dba.getCluster() mysql-js> cluster.switchToMultiPrimaryMode() mysql-js> cluster.status()
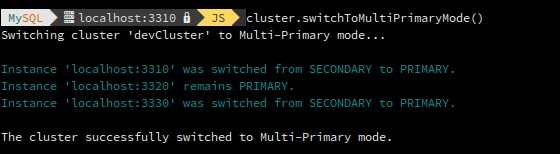
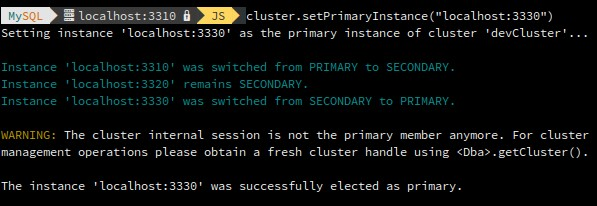
Elect a specific cluster member as the new primary.
mysql-js> var cluster = dba.getCluster()
mysql-js> cluster.setPrimaryInstance("root@prodserver3:3306")
mysql-js> cluster.status()
Using the new MySQL Shell Reporting Framework to monitor InnoDB Cluster
MySQL Shell enables you to set up and run reports to display live information from a MySQL server, such as status and performance information. MySQL Shell’s reporting facility supports both built-in reports and user-defined reports.
Download the view creation file (addition_to_sys_GR.sql) for sys schema from here
Run the script in primary server
mysqlsh --sql root@prodserver1:3306 < addition_to_sys_GR.sql
Also download the perl report here
Now install the report on your MySQL Shell client’s machine:
$ mkdir -p ~/.mysqlsh/init.d mv gr_info.py ~/.mysqlsh/init.d
Once installed, you just need to relaunch the Shell and you are ready to call the new report using the \show command:
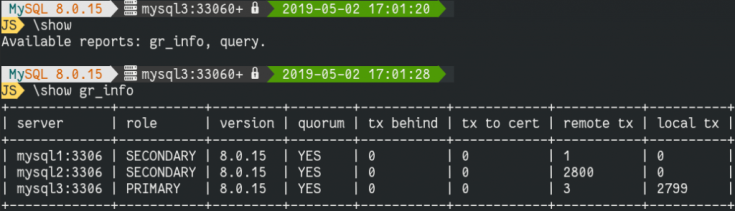
We can also use in build query report script
MySQL localhost:3320 ssl JS > \watch query select concat(member_host,':',member_port) as server, member_role as 'role', member_version as 'version', sys.gr_member_in_primary_partition() as 'quorum', Count_Transactions_Remote_In_Applier_Queue as 'tx behind', Count_Transactions_in_queue as 'tx to cert', count_transactions_remote_applied as 'remote tx', count_transactions_local_proposed as 'local tx' from performance_schema.replication_group_member_stats t1 join performance_schema.replication_group_members t2 on t2.member_id = t1.member_id
How to backup your InnoDB Cluster
Taking full backup using mysql enterprise backup
mysqlbackup --with-timestamp --backup-dir /backup backup
Download the customized backup script from here
The following query in the backup_history table gives you also an overview where the backup was taken:
mysql> SELECT backup_type, end_lsn, exit_state, member_host, member_role
FROM mysql.backup_history JOIN
performance_schema.replication_group_members ON member_id=server_uuid
Monitoring Logs
Logs are available on this file: /var/log/mysql/error.log
Warning : Timestamp
[Warning] [MY-010956] [Server] Invalid replication timestamps: original commit timestamp is more recent than the immediate commit timestamp. This may be an issue if delayed replication is active. Make sure that servers have their clocks set to the correct time. No further message
will be emitted until after timestamps become valid again.
[Warning] [MY-010957] [Server] The replication timestamps have returned to normal values.
[Warning] [MY-010956] [Server] Invalid replication timestamps: original commit timestamp is more recent than the immediate commit timestamp. This may be an issue if delayed replication is active. Make sure that servers have their clocks set to the correct time. No further message
will be emitted until after timestamps become valid again.
[Warning] [MY-010957] [Server] The replication timestamps have returned to normal values.
A timestamp is a sequence of characters or encoded information identifying when a certain event occurred, usually giving date and time of day, sometimes accurate to a small fraction of a second. It’s very important to keep your system with the good date, without this synchronisation, your cluster will fail.
Warning : member unreachable
[Warning] [MY-011493] [Repl] Plugin group_replication reported: ‘Member with address
serverdb-two-dc-1:3306 has become unreachable.’
[Warning] [MY-011493] [Repl] Plugin group_replication reported: ‘Member with address
serverdb-two-dc-1:3306 has become unreachable.’
Your member has become unreachable probably because you have : service mysql down, a network link down, set a new firewall rule or your VM is not available.
Warning : member removed
[Warning] [MY-011499] [Repl] Plugin group_replication reported: ‘Members removed from the group: serverdb-one-dc-1:3306’
[Warning] [MY-011499] [Repl] Plugin group_replication reported: ‘Members removed from the group: serverdb-one-dc-1:3306’
When a member become unreachable, it will be exclude. After have fixed your issue, use
cluster.rejoinInstance(“root@member”) to come back in normal production state.
cluster.rejoinInstance(“root@member”) to come back in normal production state.
Warning : Ip address not resolved
[Warning] [MY-010055] [Server] IP address ‘10.210.3.11’ could not be resolved: Name or
service not known.
[Warning] [MY-010055] [Server] IP address ‘10.210.3.11’ could not be resolved: Name or
service not known.
When you create a MySQL user username@ serverdb-two-dc-1 MySQL has to do a reverse lookup on every IP address connecting to it to determine whether they are part of serverdb-two-dc-1
Error : group replication pushing message
[ERROR] [MY-011735] [Repl] Plugin group_replication reported: ‘[GCS] Error pushing
message into group communication engine.
[ERROR] [MY-011735] [Repl] Plugin group_replication reported: ‘[GCS] Error pushing
message into group communication engine.
General transaction fail. Check your cluster status, it’s probably broken.
Error : group replication reach majority (quorum)
[ERROR] [MY-011495] [Repl] Plugin group_replication reported: ‘This server is not able to
reach a majority of members in the group. This server will now block all updates. The server will remain blocked until contact with the majority is restored. It is possible to use
group_replication_force_members to force a new group membership.’
[ERROR] [MY-011495] [Repl] Plugin group_replication reported: ‘This server is not able to
reach a majority of members in the group. This server will now block all updates. The server will remain blocked until contact with the majority is restored. It is possible to use
group_replication_force_members to force a new group membership.’
You have loose your quorum, fix your cluster
Error : Maximum number of connection
[ERROR] [MY-011287] [Server] Plugin mysqlx reported: ‘25.1: Maximum number of
authentication attempts reached, login failed.’
[ERROR] [MY-011287] [Server] Plugin mysqlx reported: ‘25.1: Maximum number of
authentication attempts reached, login failed.’
Main possibilities:
Your application is not set correctly
Your cluster is not set correctly (password, ip acl…)
Someone try to brute force your database access
Your application is not set correctly
Your cluster is not set correctly (password, ip acl…)
Someone try to brute force your database access
Error : Replication cannot replicate
[ERROR] [MY-011287] [Repl] Cannot replicate to server with server_uuid=’f08fbf12-8b6e11e8-9938-0050568343e5′ because the present server has purged required binary logs. The connecting server needs to replicate the missing transactions from elsewhere, or be replaced by a new server created from a more recent backup. To prevent this error in the future, consider increasing the binary log expiration period on the present server. The missing transactions are ’81f7c9c0-6576-11e8-a1d0-0050568370b9:1-14,
c9e096d7-6576-11e8-afbb-0050568370b9:1-7414160′.
[ERROR] [MY-011287] [Repl] Cannot replicate to server with server_uuid=’f08fbf12-8b6e11e8-9938-0050568343e5′ because the present server has purged required binary logs. The connecting server needs to replicate the missing transactions from elsewhere, or be replaced by a new server created from a more recent backup. To prevent this error in the future, consider increasing the binary log expiration period on the present server. The missing transactions are ’81f7c9c0-6576-11e8-a1d0-0050568370b9:1-14,
c9e096d7-6576-11e8-afbb-0050568370b9:1-7414160′.
This message is explicit, your binary logs are too old. Apply Part 6 (Recovery from zero) to fix it.
Error : Failed open relay log
[ERROR] [MY-010544] [Repl] Failed to open the relay log ‘./ serverdb-two-dc-1-relay-bingroup_replication_recovery.000001’ (relay_log_pos 4).
[ERROR] [MY-010544] [Repl] Failed to open the relay log ‘./ serverdb-two-dc-1-relay-bingroup_replication_recovery.000001’ (relay_log_pos 4).
Access problem to the binaries logs: Check your my.cnf configuration.
Error : Master initialization
[ERROR] [MY-010426] [Repl] Secondary: Failed to initialize the master info structure for
channel ‘group_replication_recovery’; its record may still be present in
‘mysql.secondary_master_info’ table, consider deleting it.
[ERROR] [MY-010426] [Repl] Secondary: Failed to initialize the master info structure for
channel ‘group_replication_recovery’; its record may still be present in
‘mysql.secondary_master_info’ table, consider deleting it.
You have probably tried to configure again your cluster, with a previous configuration existing. If you want to reconfigure your cluster from zero, clean it before.
Error : Network failure
[ERROR] [MY-011505] [Repl] Plugin group_replication reported: ‘Member was expelled from the group due to network failures, changing member status to ERROR.’
[ERROR] [MY-011505] [Repl] Plugin group_replication reported: ‘Member was expelled from the group due to network failures, changing member status to ERROR.’
This message is explicit, your network link has failed.

Great article, thank you for sharing this great article with us.
ReplyDeleteMysql DBA Tutorial